GPT-4o API의 구조화된 출력 기능 활용 가이드
참고 : https://platform.openai.com/docs/guides/structured-outputs/examples
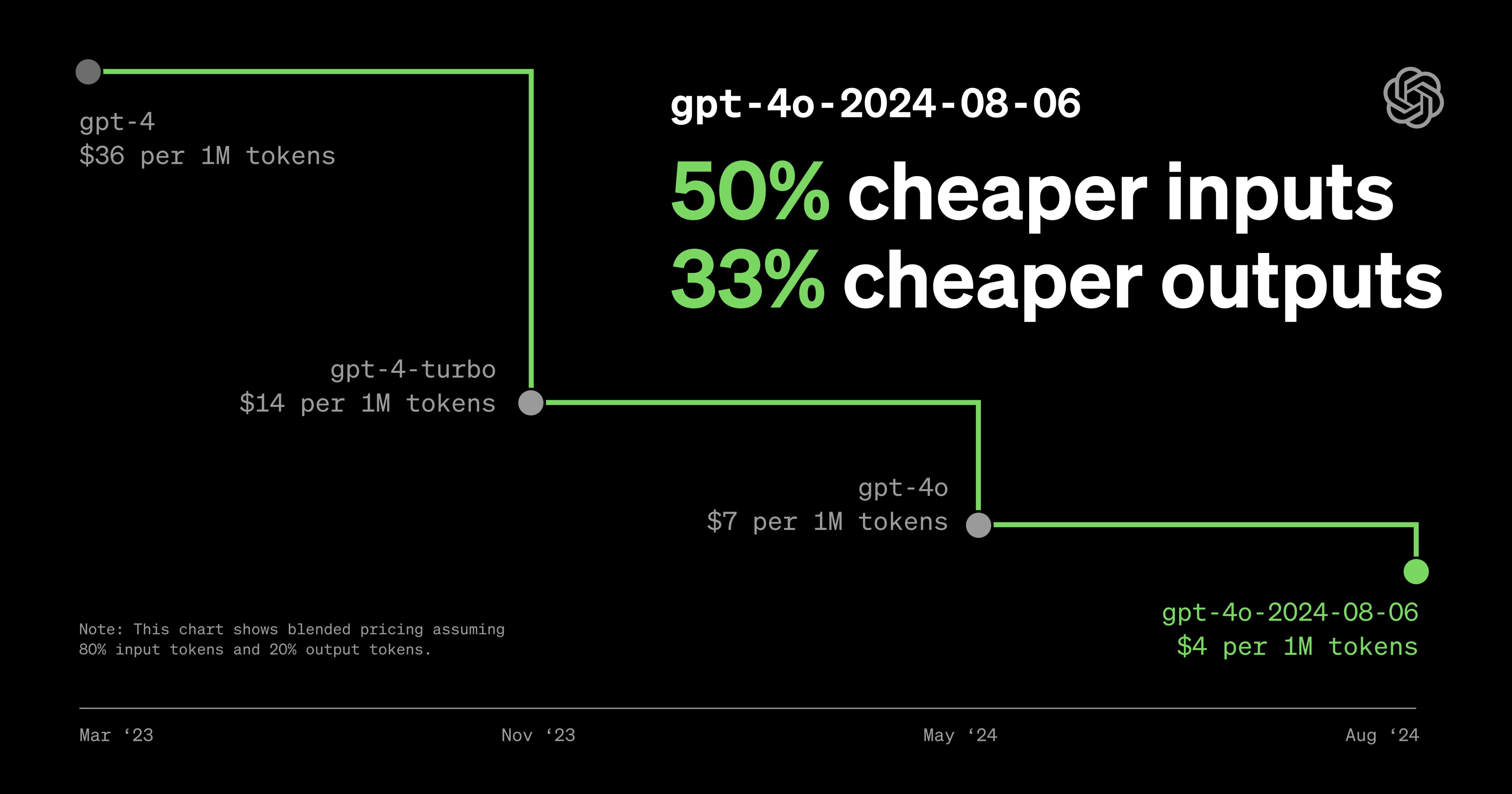
gpt-4o 모델의 새로운 버전인 gpt-4o-2024-08-06 가 공개되었습니다!
같은 4o 모델보다 인풋과 아웃풋이 50%, 33% 저렴합니다.
출력을 JSON 포맷으로 강제할 수 있는 json mode 기능의 강화 버전인 Structured Outputs 기능또한 추가되었습니다.
이전까지 response_format으로 "json-output" 을 설정할 경우 응답의 내용이 JSON 형태로 출력되긴 했지만, 입력 프롬프트에 JSON 형식 예시를 직접 작성해야 했습니다. 이는 입력 토큰 수를 증가시키는 문제가 있었습니다. 또한, 여러 번의 반복 작업을 수행할 때 지정한 키를 일관되게 유지하지 못해, 결과 저장 시 파싱 오류를 일으키거나 원하는 결과를 얻기 위해 여러 번의 요청을 해야 하는 경우가 있었습니다. 이제 Structured Output 기능을 활용해 안정적인 포맷과 스키마의 응답을 얻을 수 있습니다.
이제 새로운 모델과 GPT-4o API의 구조화된 출력 기능을 활용하는 방법을 단계별로 살펴보겠습니다.
1. 환경 설정
먼저 필요한 라이브러리를 설치하고 임포트합니다.
구글 코랩 환경이라면, openai 라이브러리를 매번 설치해야 합니다.
!pip install openaiimport json, os
from openai import OpenAI
import pandas as pdopenai의 api key는 사용하여 호출시 돈이 나가기 때문에 반드시 다른 곳에 안전하게 보관하고, load해서 사용하자
2. API 키 설정
OpenAI API를 사용하기 위해서는 API 키가 필요합니다. 보안을 위해 API 키는 별도의 파일에 저장하고 불러오는 것이 좋습니다.
OPENAI_API_KEY = json.load(open("내 api 저장 경로"))["openai_api_key"]client = OpenAI(api_key=OPENAI_API_KEY)3. API 연결 테스트
API가 정상적으로 작동하는지 간단한 테스트를 수행합니다.
client.chat.completions.create(
model="gpt-4o-2024-08-06",
max_tokens=4096,
messages=[
{"role": "user", "content": "Hi, I'm Jay. Who are you?"},
]
)ChatCompletion(id='chatcmpl-9uC8q8gzo50y7ghw7RuQOLYhTAFMW', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content="Hi Jay! I'm ChatGPT, an AI language model developed by OpenAI. I'm here to help answer questions, provide information, or just chat. How can I assist you today?", refusal=None, role='assistant', function_call=None, tool_calls=None))], created=1723180068, model='gpt-4o-2024-08-06', object='chat.completion', service_tier=None, system_fingerprint='fp_2a322c9ffc', usage=CompletionUsage(completion_tokens=37, prompt_tokens=16, total_tokens=53))4. 유틸리티 함수 정의
보통 우리가 관심이 있는 것은 위와 같은 긴 response 중에서 content="Hello Jay! I'm an AI developed by OpenAI, and I'm here to help you with information, answer questions, or assist with various tasks. How can I assist you today?" 뿐이기 때문에 간단하게 API를 호출하고, 응답 처리를 하기 위한 유틸리티 함수를 정의합니다.
# 요청 하여 응답 얻는 함수
def get_response(client, model, r_format, messages):
completion = client.beta.chat.completions.parse(
model=model,
temperature=0.1,
stop=['</json>',],
response_format=r_format,
messages=messages
)
return completion# 응답 중 메시지 내용만 파싱하는 함수 만들기
def get_contents(response):
return response.choices[0].message.content분석할 이미지를 표시하기 위한 함수를 정의합니다. 이 함수는 이미지의 원본 비율을 유지하면서 크기를 조정합니다.
# 원본 비율을 유지하면서 이미지를 출력하려면, 사용자가 지정한 width 또는 height 중 하나만 설정하고, 다른 값을 자동으로 계산해야 합니다. 이렇게 하면 이미지가 원본 비율을 유지하면서 크기 조정됩니다.
from IPython.display import Image, display
from PIL import Image as PILImage
import requests
from io import BytesIO
def show_img(img_url, width=None, height=None):
# 원본 이미지의 크기 가져오기
response = requests.get(img_url)
img = PILImage.open(BytesIO(response.content))
orig_width, orig_height = img.size
# 비율 유지하면서 크기 계산
if width is not None and height is None:
height = int((width / orig_width) * orig_height)
elif height is not None and width is None:
width = int((height / orig_height) * orig_width)
elif width is None and height is None:
width, height = orig_width, orig_height
display(Image(url=img_url, width=width, height=height))함수가 잘 동작하는지 테스트 해보는 텍스트-투-텍스트 예제
messages = [{"role": "user", "content": "Hi, I'm Jay. Who are you? Please answer in json format {'answer':''}"}]
json_format = {"type": "json_object"}
response = get_response(client, "gpt-4o-2024-08-06", json_format, messages)
get_contents(response)'{"answer":"Hello Jay, I\'m an AI language model here to assist you with any questions or information you need."}'5. 새로운 모델 gpt-4o-2024-08-06 테스트 해보기
img_url = "https://cdn.pixabay.com/photo/2015/09/04/23/00/vintage-922963_1280.jpg"show_img(img_url, width=300)
system_prompt = "Please Extract Text, and image elements in the input image and elebolate the details. Please answer in json format {'Text':'','Image':''}"
system_prompt = """
Please Extract Text, and image elements in the input image and elebolate the details.
Please answer in json format {'Text':'','Image':''}
"""messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": [{
"type": "image_url",
"image_url": {"url": img_url}
}]}
]response_1= get_response(client, "gpt-4-turbo", json_format, messages)
get_contents(response_1)'{\n "Text": "VANITY FAIR, June, 1914 - Price 25 cts.",\n "Image": "The image is a cover of Vanity Fair magazine from June 1914. It features an illustration of five stylishly dressed figures, likely at a social event. The characters are depicted in early 20th-century fashion, with large hats and elegant outfits. The women are wearing long dresses and hats adorned with feathers and bows, while the young boy is in a sailor suit. The background includes a faint outline of architectural structures, possibly indicating an outdoor setting like a park or a racecourse. The overall style of the illustration is playful and colorful, typical of magazine art from that era."\n}'response_2= get_response(client, "gpt-4o-2024-08-06", json_format, messages)
get_contents(response_2)'{"Text":"VANITY FAIR\\nJune, 1914 - Price 25 cts.","Image":"The image is an illustration of four fashionably dressed individuals, likely women, in early 20th-century attire. They are wearing hats and stylish clothing with stripes and patterns. A small dog is also present in the foreground. The background suggests an urban setting with a carriage and buildings."}'가장 좋은 성능을 낸다고 알려진 "gpt-4-turbo" 모델과 "gpt-4o-2024-08-06" 모델의 출력을 비교해보면, output의 길이기 좀 더 짧아지고 간결하고 핵심적인 객관적인 묘사를, "gpt-4-turbo"모델은 의상의 특징, 배경등에 대한 보다 상세한 묘사를 제공합니다.
response_1.usage.completion_tokens, response_2.usage.completion_tokens(147, 79)6. 아웃풋 형식 지정 형태에 따른 결과물 비교
6-1. 시스템 프롬프트는 그대로 두고, 요청 시에 output_format을 빼고 요청해보기
response_3 = client.beta.chat.completions.parse(
model="gpt-4o-2024-08-06",
temperature=0.1,
stop=['</json>',],
messages=messages
)get_contents(response_3)'```json\n{\n "Text": "VANITY FAIR\\nJune, 1914 - Price 25 cts.",\n "Image": "The illustration features four fashionably dressed individuals in early 20th-century attire. They are standing in a street scene with a carriage and a small dog in the background. The clothing includes hats, striped pants, and a mix of green, blue, and pink colors."\n}\n```'type(get_contents(response_3))str예시와 같은 형태로 답변을 생성하긴 했지만, 답변 내용의 기본 타입은 문자열입니다. 여러 번 실행해보면, 딕셔너리를 끝내는 괄호가 빠져 닫히지 않은 결과물을 내놓는 등의 오류가 발생하기도 합니다.
6-2. 원래의 system prompt에서 출력 형식 부분 조정
system prompt에서 json_output의 예시에 대한 지문을 빼고, json 포맷으로 출력하라는 메시지만 남기고 실행해보기
system_prompt= """
Please Extract Text, and image elements in the input image and elebolate the details.
Please answer in json format.
"""
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": [{
"type": "image_url",
"image_url": {"url": img_url}
}]}
]response_4 = get_response(client,"gpt-4o-2024-08-06",json_format,messages)get_contents(response_4)'{\n "text": {\n "title": "VANITY FAIR",\n "date": "June, 1914",\n "price": "Price 25 cts."\n },\n "elements": [\n {\n "type": "people",\n "description": "Four fashionably dressed individuals, three women and one child, in early 20th-century attire."\n },\n {\n "type": "animal",\n "description": "A small dog at the bottom left corner."\n },\n {\n "type": "background",\n "description": "A sketch of a carriage and a building in the background."\n }\n ],\n "artist_signature": "M. Plummer"\n}'형식은 json_format으로 나오지만, 딕셔너리 키로 어떤 값들이 나와야 하는지 구체적으로 지정해주지 않았기 때문에, 요청할 때마다 비일관적인 답들이 나오게 됩니다.
아예 출력 형식에 대한 어떠한 코멘트도 없이 실행해보면,
system_prompt= """
Please Extract Text, and image elements in the input image and elebolate the details.
"""
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": [{
"type": "image_url",
"image_url": {"url": img_url}
}]}
]
response_5 = client.beta.chat.completions.parse(
model="gpt-4o-2024-08-06",
temperature=0.1,
messages=messages
)get_contents(response_5)'This is a vintage cover of Vanity Fair magazine from June 1914. The illustration features four stylishly dressed individuals in early 20th-century fashion. They are wearing a mix of striped and patterned outfits, with hats and accessories typical of the era. In the background, there is a carriage and a small dog in the foreground. The text at the bottom reads "June, 1914 - Price 25 cts." The artwork is signed by the artist, possibly with the name "Plummer."'출력에 대한 아무런 요청 사항이 없으므로 일반적인 문자열로 결과가 생성되게 됩니다.
7. Structured_output
참고 : https://platform.openai.com/docs/guides/structured-outputs/structured-outputs
Pydantic을 사용하여 구조화된 출력을 정의하고 활용해봅니다.
Structured Output을 사용하면 결과물의 구조를 더 엄격하게 제어할 수 있습니다. 이 방식은 복잡한 출력 구조가 필요한 경우에 특히 유용합니다.
from pydantic import BaseModel
from openai import OpenAI
client = OpenAI(api_key=OPENAI_API_KEY)
class ImageCaptionEvent(BaseModel):
Text: str
Image: str
system_prompt= """
Please Extract Text, and image elements in the input image and elebolate the details.
"""
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": [{
"type": "image_url",
"image_url": {"url": img_url}
}]}
]
response_5 = client.beta.chat.completions.parse(
model="gpt-4o-2024-08-06",
temperature=0.1,
messages=messages,
response_format=ImageCaptionEvent
)get_contents(response_5)'{"Text":"Vanity Fair\\nJune, 1914 - Price 25 cts.","Image":"The image is a vintage cover of Vanity Fair magazine from June 1914. It features an illustration of four elegantly dressed women in fashionable attire of the time, with a small dog at their feet. The background suggests a street scene with a carriage and buildings. The women are wearing hats and long dresses with bold patterns and colors, indicative of early 20th-century fashion."}'response_2.usage.completion_tokens, response_5.usage.completion_tokens(80, 97)response_2.usage.prompt_tokens, response_5.usage.prompt_tokens(1147, 1140)결과물은 더 길어지고, 프롬프트는 더 짧아진 결과를 얻었다. 이 예시는 기대하는 output이 그렇기 복잡하지 않았는데, 구조적 response의 결과가 수십개 키의 값이 되길 원하는 경우라면 그 만큼 프롬프트도 길어지게 되어 이렇게 structured out으로 정의한 포맷을 지키게 하는 것의 유용성이 더 커질 것이다.
8. 결론
GPT-4o API의 구조화된 출력 기능은 일관된 형식의 응답을 얻는 데 매우 유용합니다. 여러 인풋에 대하여 일관 특히 복잡한 출력 구조가 필요한 경우, Pydantic 모델을 사용한 Structured Output 방식이 효과적입니다. 이 방법을 통해 프롬프트의 길이를 줄이면서도 원하는 형식의 응답을 얻을 수 있어, API 사용의 효율성을 크게 높일 수 있습니다.
'Deep Learning' 카테고리의 다른 글
| GPT-4를 활용하여 여러 장의 이미지를 사용한 few-shot learning 하기 (0) | 2024.08.09 |
|---|---|
| 딥러닝 모델 멀티GPU 분산학습하는 법 (0) | 2023.06.15 |
| Q. GPU 작업 모니터 편리하게 하는 방법은? (0) | 2022.11.08 |
| [GAN 첫걸음] 진짜 쉽게 설명해주는 GAN (0) | 2021.07.28 |
| [AI class w10d4] 신경망 기초 - 순환 신경망 (0) | 2021.07.03 |