Contents
CNN기반의 Visual Recognition
1. 딥러닝 기반의 영상 인식
2. Convolutional Neural Network
3. 전이학습
Visual Recognition의 정의
: 카메라를 통해 취득되는 사진이나 동영상에서 정보를 취득하는 과정

딥러닝리뷰
딥러닝은 deep neural network을 통해 학습(learning)하는 것
층(레이어, layer)의 갯수가 3개 이하이면 얕은층 신경망, 4개 이상이면 심층 신경망




비선형 함수의 필요성
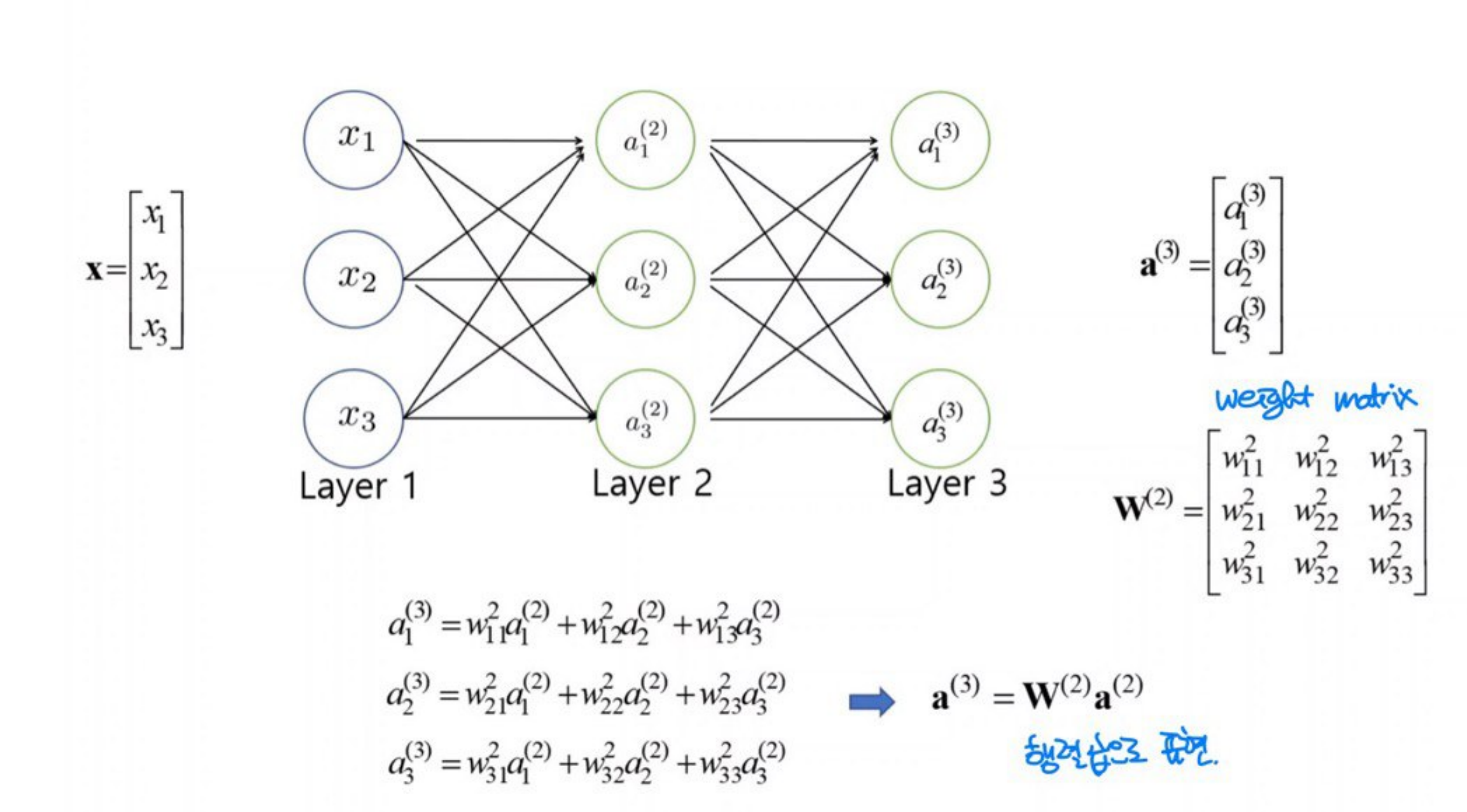
NN은 1개의 벡터(텐서)를 다른 벡터로 매핑하는 함수라고 볼 수 있다.

위의 NN은 X를 $a^{(3)}$으로 매핑하는 함수
만약 $W^{(1)}$와 $W^{(2)}$의 사이에 어떤 비선형적인 함수가 없다면, $W^{(2)}W^{(1)}$은 $W$와 같아짐
-> 결국 2개의 행렬로 표현되는 NN을 1개의 행렬로 표현할 수 있어, 2개의 레이어를 가진 NN과 다를 게 없어진다.
깊은 layer를 쌓은 의미가 없어진다.
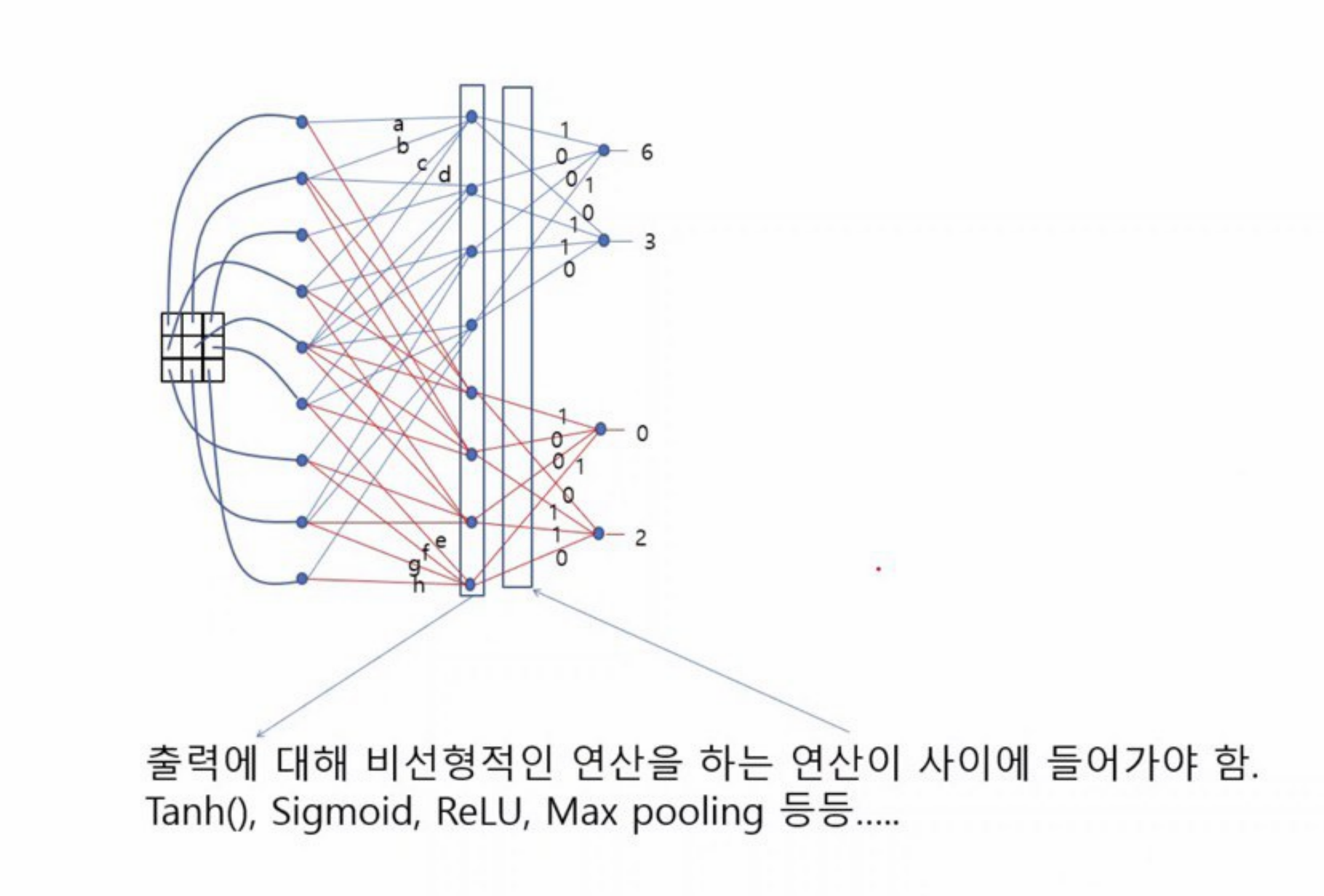
-> 출력에 대해 비선형적인 연산을 하는 연산이 사이에 들어가야 함.
Tanh(), Sigmoid, ReLU, Max Pooling 등....

딥러닝 기반 영상 인식 (Recognition) 문제
1. 음성인식
정확한 그림은 아니고 단순화시킨 그림
음성 : 공기의 파동 -> 스마트폰에서 센서로 인식 -> 전기 신호로 변환 -> 샘플링을 통해 디지털 신호로 변환

2. 영상인식
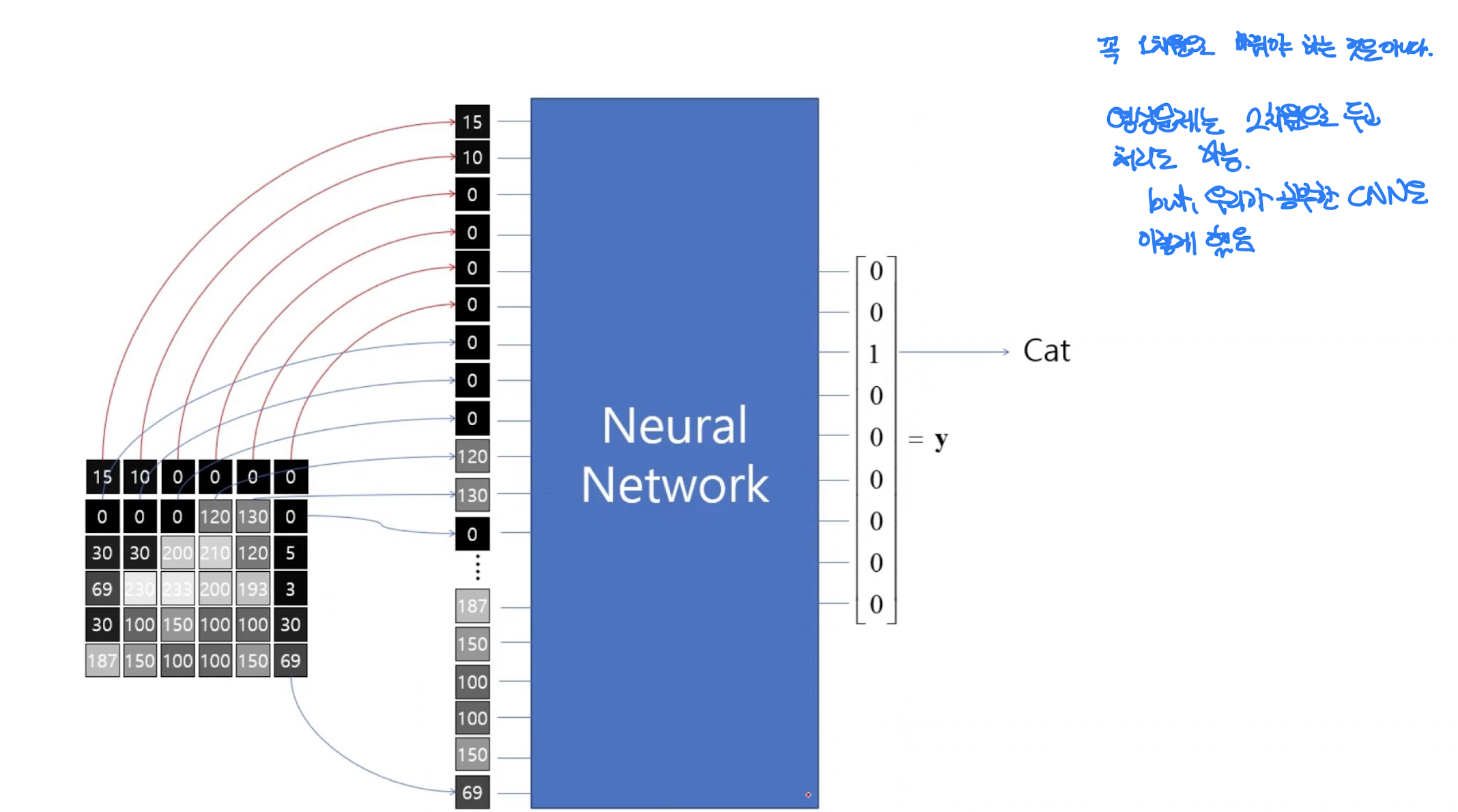
디지털 영상 : 정수의 2-D 배열 -> 정수의 의미 : 그 화소의 밝기
만약 컬러라면 채널 3개 x3


3. 인식, 예측의 문제는 곧 분류(classification), regression의 문제이다.
음성인식: 사람별로 목소리를 분류하여 새로운 음성이 어느 분류에 들어가는지 판단
영상인식: 종류별로 영상을 분류하여 새로운 영상이 어느 분류에 들어가는지 판단

영상 인식 심플 예제
1. 2x2 영상

사람 영상과 개 영상의 차이가 다음과 같을 때,
1. 이미지 전처리로 평균을 빼줌 (지금은 batch normalization하기 때문에 필요없음)
2. 2개 layer로 구성된 네트워크를 만들었음
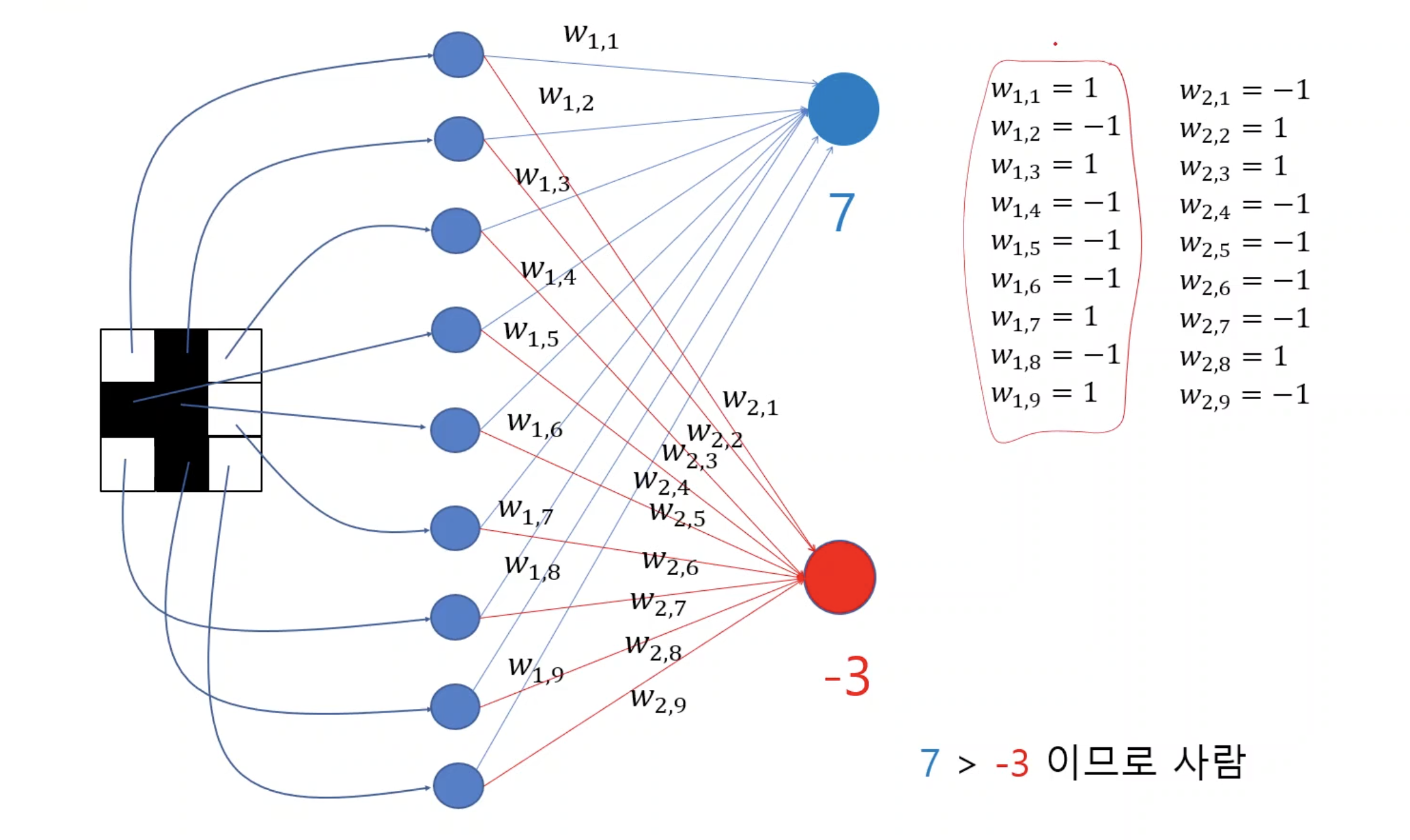
만약 $W_{1,1}$, $W_{1,2}$, $W_{1,3}$, $W_{1,4}$ 이 각각 -1 또는 1의 값만 가지고 있을 때(simple하게 하기 위해), 사람의 영상이 입력으로 들어갈 때, A를 가장 크게 하는 $W_{1,1}$, $W_{1,2}$, $W_{1,3}$, $W_{1,4}$의 값은?
$W_{1,1} = -1$, $W_{1,2} = 1$, $W_{1,3} = 1$, $W_{1,4} = -1$인 weight가 사람 영상에 대해 A 노드를 activate 시킨다.
마찬가지로 $W_{2,1} = 1$, $W_{2,2} = -1$, $W_{2,3} = -1$, $W_{2,4} = 1$인 weight가 개 영상에 대해 B 노드를 activate 시킨다.

-> weight들이 원본 영상과 똑같이 생겼을 때 activate되었다.
2. 3x3 영상

3x3일 때도 마찬가지이다. 가장 마지막 layer에 classification 갯수만큼의 노드가 있고, 그 노드의 값이 가장 크면, 그 object로 분류한다.
그 값이 가장 커지게 만들어주는 가중치의 쌍이 있다.

실제로는 정해진 weight값이 미리 있는 것이 아니라 학습과정을 통해 weight값들을 학습하게 된다.
3. 모델의 학습


모델을 만든 다음 test time 때 우리가 학습한 데이터와 같은 input만 들어오는 것이 아니다.

똑같지 않아도 추론하여 판정이 가능하다.
이 NN은 (1, 9) 벡터를 (1, 2) 벡터로 매핑 시키는 함수이다.
Convolution 연산
convolutional map



이런식으로 필터가 sliding 하면서 계산한 값을 채워 나간다.
convolution neural network을 살펴보자

y1은 모든 픽셀과 연결된 것이 아니라, filter와 일치하는 픽셀들과만 연관되어 weights를 연산해준다. (fully conneted 가 아니다)

앞에서 보여준 neural network는 convolution으로 표현이 가능

역으로 $y_{1}$에서 가장 큰 값을 보였다면 이것이 의미하는 바는?
-> $y_{1}$ 영역에 귀가 있다.

CNN filters
convulutional neural networks : 레이어가 올라갈수록 보다 복합적인 사실(추상화)을 전달해준다.

뇌에서 시각 정보를 처리하는 구조와 유사하다고 평가받고 있다.
설명 가능한

AI (XAI) : 요즘 주목받는 트렌드
CNN의 특징 : filter가 있다.
그 필터가 슬라이딩하면서 input이미지와 필터가 가장 유사한 공간에서 가장 큰값 -> activate 된다
참고 : https://adeshpande3.github.io/A-Beginner's-Guide-To-Understanding-Convolutional-Neural-Networks/
Multi-channel Convolution
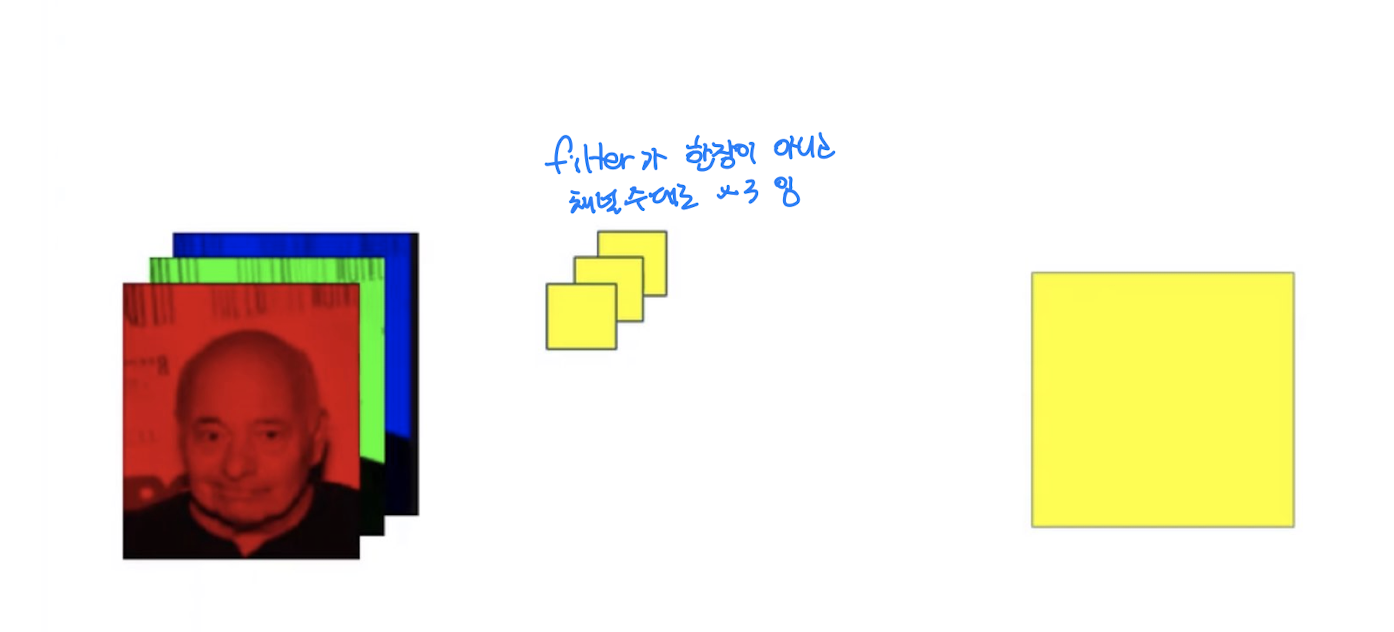
컬러 영상은 한 장이 RGB 컬러 세 개의 채널로 구성되어있는 형태
하나의 픽셀은 각 채널에서 단일한 값을 가지고 있다.

필터가 sliding 할 때도 R, G, B 채널 각각 계산한다음 더해준다.


아웃풋 채널의 갯수는 필터의 갯수와 같다.
참고 영상 : https://www.youtube.com/watch?v=jajksuQW4mc

CNN의 input은 4차원임
영상은 3차원(height, width, channels) , num_img 까지

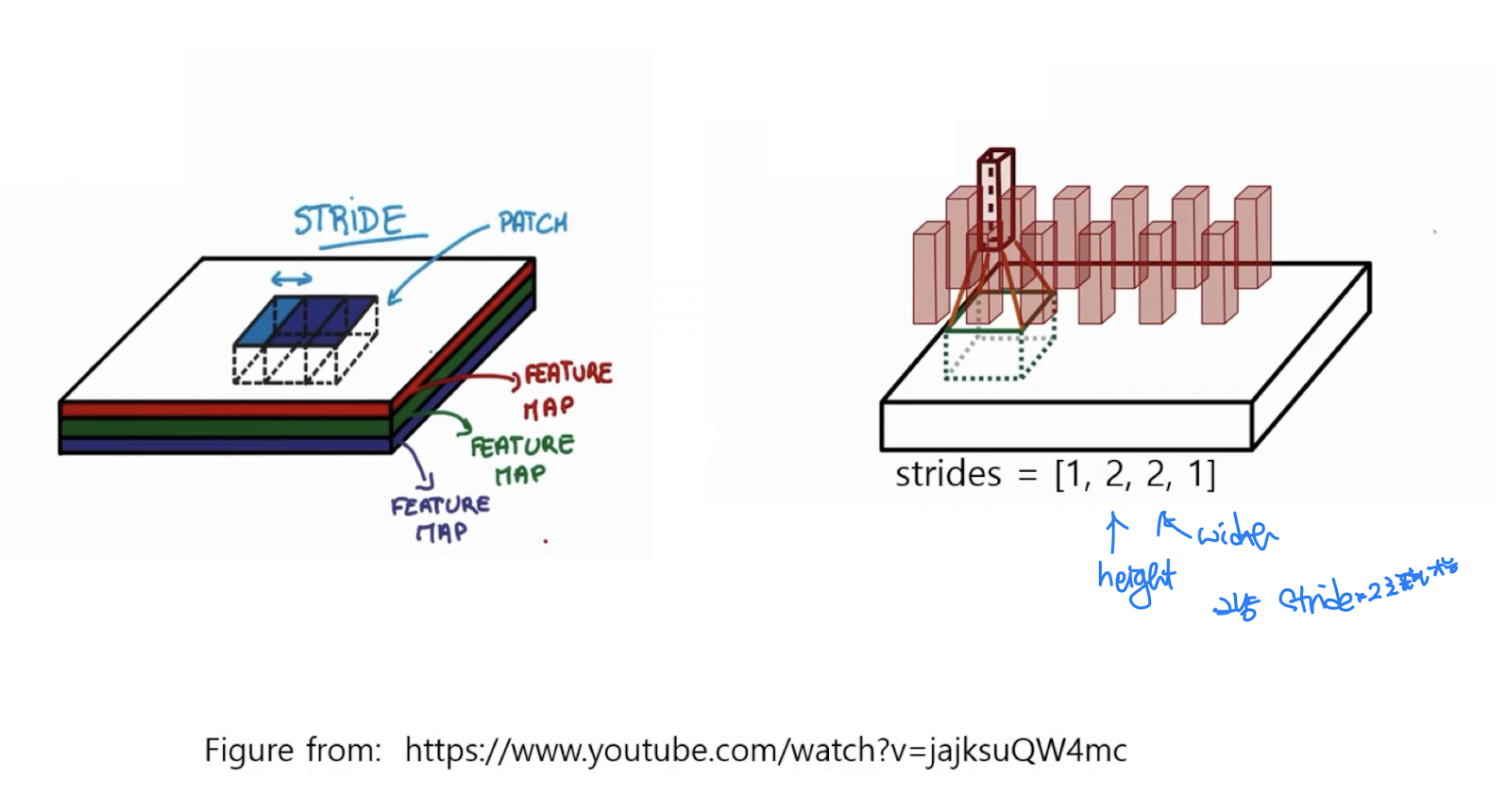
stride= 2이면, 높이도 1/2, 넓이도 1/2 되기 때문에 원본 영상 크기보다 1/4인 결과를 얻게 됨
CNN도 matrix로 표현 가능하다.
단, 0이 많은 매트릭스

conv layer + non-linear+ conv layer + ....반복하다가 마지막에 softmax함수를 통과하여 output vector가 나오게 됨 (multi-label classification 문제인 경우)
비선형 함수(Non-linear function)

비선형 함수 계산도 각 픽셀마다 해준다. -> 모든 픽셀이 0~1사이의 값을 가지게 된다.



풀링을 하게 되면, 정해진 단위 내에서 가장 큰 값을 남기기 때문에, 그 단위 내에서 어떤 위치였는지는 상관이 없다.
그래서 약간 다른 이미지도 풀링 통과 뒤에는 같은 값을 가지게 될 수 있으며, 미세한 변화가 있어도 결과가 달라지지 않게 하는 (invariance를 높이는) 효과가 있다.
CNN 구조

fully connect : 전체 픽셀을 해당 노드와 연결시킴
CNN filter: 역전파를 하게 되면 자동으로 이런 특성들이 추출되게 됨

실습 - CNN을 활용한 폐렴 검출
https://www.kaggle.com/kashyapgohil/pneumonia-detection-using-cnn/
Pneumonia Detection using CNN
Explore and run machine learning code with Kaggle Notebooks | Using data from Chest X-Ray Images (Pneumonia)
www.kaggle.com
이런 의료 진단 관련 task는 label 간 불균형이 심함
이를 어떻게 해결할 것인가??
-> 분포를 맞춰줘야한다.
1) 비정상 데이터를 aumentation해서 늘려준다.
2) 정상 데이터를 random하게 줄여준다.
3) batch에 들어갈 데이터를 뽑을 때 label 0/1 분포가 같아지도록 뽑는다.
--> 이 노트북에서는 1. augmentation을 활용하였다.
*추가 참고 내용 (http://data-newbie.tistory.com/155)
평가에서도 단순히 accuracy만 보면 안된다.
Sensitivity(Recall, True Positive Rate)
TP/(TP + FN) 즉, 실제로 positive인데 내가 positive라고 잘 예측한 확률
Precision
TP/(TP + FP) 즉, 내가 positive라고 예측한 것 중에 진짜 positive인 확률
F1 score
2*(precision*sensitivity)/(precision+sensitivity)
-> imbalance data를 볼 때 주로 사용
전이학습 (transfer learning)
전이학습의 필요성
- 일부 기업외에는 막대한 데이터를 지니고 있기가 어려움
- 양질의 데이터, 신뢰할 수 있는 데이터가 필요함
- 학습할 수 있는 컴퓨팅 파워에 한계가 있음
→기존의 학습된 모델을 이용할 수 있으면 도움이 됨
→전이학습은 딥러닝을 중소기업 등에서도 활용 가능하게 하는 중요한 방법

1. 사전학습 모델을 그대로 사용
모델의 파라미터를 변형하기 않고 사용 - 문제가 거의 같을 때 사용
Ex) ImageNet데이터로 학습된 모델을 개와 고양이를 분류하는 문제에 사용
(이미 이미지넷 분류클래스에 개/고양이 있음)
2. 전이학습 방법-1 : 모델 분류기만 재학습
문제가 비슷할 때 사용
Ex) ImageNet데이터로 학습된 모델을 어벤져스 캐릭터 분류 문제에 사용
(어벤저스 캐릭터를 분류한 적은 없지만, 많은 사람 이미지를 학습하고 사람으로 분류한다)
3.전이학습 방법-2 : 모델의 일부를 동결해제하여 재학습
문제가 약간 다를 때 사용
Ex) ImageNet데이터로 학습된 모델을 얼굴인식 문제에 사용
(이미지에서는 얼굴과 얼굴 간의 차이(매우 미세한 차이)를 인식하는 학습을 한 적이 없다.)
4. 전이학습 방법-3 : 모델의 파라미터 전체를 미세조정
문제가 많이 다를 때 사용
Ex) ImageNet데이터로 학습된 모델을 의료영상 문제에 사용
(이미지넷에서 학습한 방대한 자료들과는 상당히 다른 특징을 가진 데이터 low level layer부터 재학습이 필요할 수 있다)
- 그럴꺼면 처음부터 새롭게 학습하는 것과 뭐가 다른가?
초기에 이미지넷에서 학습된 weight 수치가 있기 때문에 시작점이 그래도 다르다 -> fine tuning!
실습해보기
1. Image downloader를 이용하여 원하는 클래스에 해당하는 사진을 일괄 다운로드
2. 클래스별로 폴더를 만들어서 클래스 별로 사진을 폴더에 넣기
3. 클래스별로 사진을 읽어들여서 전이학습시키기
실습 2-1
사용자 정의의사전학습모델을 이용한 전이학습
실습 2-2
Keras 사전학습모델을 이용한 전이학습
실습 2-3
Tensor flowHub를 이용한 전이학습
TensorFlow Hub
tfhub.dev
다음 페이지에서 tensorflow HUB로 미세조정(fine tuning)에 대한 예제
https://www.tensorflow.org/hub/common_saved_model_apis/images?hl=ko
이미지 작업을 위한 일반적인 SavedModel API | TensorFlow Hub
이 페이지에서는 이미지 관련 작업용 TF2 SavedModel에서 Reusable SavedModel API를 구현하는 방법을 설명합니다. (이는 현재 지원 중단된 TF1 Hub 형식의 이미지에 대한 일반적인 서명을 대체합니다.) 이미
www.tensorflow.org