Contents
1. 4일차 숙제 리뷰
2. 트랜잭션 소개와 실습
3. 기타 고급 문법 소개와 실습
4. 맺음말
1. 4일차 숙제 리뷰
1. 사용자별 처음과 마지막 채널 찾기
ROW_NUMBER를 활용해보자 (셀렉트된 레코드들에 특정 기준에 따른 일련번호를 부여하는 것)
--1. CTE 방식으로 해결
WITH first AS ( -- 모든 사용자 별로 첫 번째 리턴
SELECT userid, ts, channel, ROW_NUMBER() OVER(PARTITION BY userid ORDER BY ts) seq
FROM raw_data.user_session_channel usc
JOIN raw_data.session_timestamp st ON usc.sessionid = st.sessionid
), last AS ( -- 모든 사용자 별로 마지막 리턴 (DESC 사용하여)
SELECT userid, ts, channel, ROW_NUMBER() OVER(PARTITION BY userid ORDER BY ts DESC) seq
FROM raw_data.user_session_channel usc
JOIN raw_data.session_timestamp st ON usc.sessionid = st.sessionid
)
SELECT first.userid AS userid, first.channel AS first_channel, last.channel AS last_channel
FROM first
JOIN last ON first.userid = last.userid and last.seq = 1
WHERE first.seq = 1; -- 일반적으로 FROM table에서 쓰는 필터를 WHERE에 붙임-- 2. JOIN 방식으로 해결
SELECT first.userid AS userid, first.channel AS first_channel, last.channel AS last_channel
FROM ( -- 1.번에서 WITH 문 에 왔던 first, last 가 FROM 과 JOIN 자리로 옴
SELECT userid, ts, channel, ROW_NUMBER() OVER(PARTITION BY userid ORDER BY ts) seq
FROM raw_data.user_session_channel usc
JOIN raw_data.session_timestamp st ON usc.sessionid = st.sessionid
) first
JOIN (
SELECT userid, ts, channel, ROW_NUMBER() OVER(PARTITION BY userid ORDER BY ts DESC) seq
FROM raw_data.user_session_channel usc
JOIN raw_data.session_timestamp st ON usc.sessionid = st.sessionid
) last ON first.userid = last.userid and last.seq = 1
WHERE first.seq = 1;-- 3. GROUP BY 방식
SELECT userid,
MAX(CASE WHEN rn1 = 1 THEN channel END) first_touch,
MAX(CASE WHEN rn2 = 1 THEN channel END) last_touch
FROM (
SELECT userid,
channel,
(ROW_NUMBER() OVER (PARTITION BY usc.userid ORDER BY st.ts asc)) AS rn1,
(ROW_NUMBER() OVER (PARTITION BY usc.userid ORDER BY st.ts desc)) AS rn2
FROM raw_data.user_session_channel usc
JOIN raw_data.session_timestamp st ON usc.sessionid = st.sessionid
)
GROUP BY 1;-- 4. FIRST_VALUE / LAST_VALUE(첫번째 행 / 마지막 행을 가져오는 명령어)
SELECT DISTINCT
A.userid,
FIRST_VALUE(A.channel) over(partition by A.userid order by B.ts
rows between unbounded preceding and unbounded following) AS First_Channel,
LAST_VALUE(A.channel) over(partition by A.userid order by B.ts
rows between unbounded preceding and unbounded following) AS Last_Channel
FROM raw_data.user_session_channel A
LEFT JOIN raw_data.session_timestamp B ON A.sessionid = B.sessionid
ORDER BY 1;2. gross revenue 가 가장 큰 사용자 ID 10개 찾기
-- 1. GROUP BY
SELECT
userID,
SUM(amount)
FROM raw_data.session_transaction st
LEFT JOIN raw_data.user_session_channel usc ON st.sessionid = usc.sessionid
GROUP BY 1
ORDER BY 2 DESC
LIMIT 10;-- 2. SUM OVER
SELECT DISTINCT -- 중복 레코드가 많기 때문에 DISTINCT가 필요
usc.userid,
SUM(amount) OVER(PARTITION BY usc.userid) --GROUP BY 와는 달리 userid별로 그루핑 된 것은 아니다
FROM raw_data.user_session_channel AS usc
JOIN raw_data.session_transaction AS revenue ON revenue.sessionid = usc.sessionid
ORDER BY 2 DESC
LIMIT 10;3. 월별 NPS 계산하기
SELECT month,
ROUND((promoters-detractors)::float/total_count*100, 2) AS overall_nps
FROM ( -- 달별로 하나씩 만들어줌
SELECT LEFT(created, 7) AS month,
COUNT(CASE WHEN score >= 9 THEN 1 END) AS promoters,
COUNT(CASE WHEN score <= 6 THEN 1 END) AS detractors,
COUNT(CASE WHEN score > 6 AND score < 9 THEN 1 END) As passives,
COUNT(1) AS total_count
FROM raw_data.nps
GROUP BY 1
ORDER BY 1
);SELECT LEFT(created, 7) AS month,
ROUND(SUM(CASE
WHEN score >= 9 THEN 1
WHEN score <= 6 THEN -1 END)::float*100/COUNT(1), 2)
FROM raw_data.nps
GROUP BY 1
ORDER BY 1;2. 트랜잭션 소개와 실습
1. 트랜잭션이란?
- atomic하게 실행되어야 하는 SQL들을 묶어서 하나의 작업처럼 처리하는 방법
- 이는 DDL이나 DML 중 레코드를 수정/추가/삭제한 것에만 의미가 있음
- SELECT에는 트랜잭션을 이용할 이유가 없음
- BEGIN과 END 혹은 BEGIN과 COMMIT사이에 해당 SQL들을 사용 (사이에 에러가 발생하면 rollback되버림)
- ROLLBACK
- 은행 계좌 이체가 아주 좋은 예
- 계좌 이체: 인출과 입금 두 과정으로 이루어짐
- 만일 인출은 성공했는데 입금은 실패한다면?
- 이 과정은 동시에 성공하던지 실패해야 함 -> atomic
- 이런 과정들을 트랜잭션으로 묶어줘야 함
- 조회만 한다면 이는 트랜잭션으로 묶일 이유가 없음
-
BIGIN; A의 계좌로부터 인출; B의 계좌로 입금; -- 이 명령어들은 마치 하나의 명령어처럼 처리됨. 다 성공하던지 다 실패하던지 둘중의 하나가 됨 END;- END와 COMMIT은 동일
- 만일 BEGIN 전의 상태로 돌아가고 싶다면 ROLLBACK 실행
- 이 동작은 commit mode에 따라 달라짐
- 트랜잭션 커밋모드 :autocommit
- autocommit = True
- 모든 레코드 수정/삭제/추가 작업이 기본적으로 바로 데이터베이스에 쓰여짐 이를 커밋된다고 한다
- 기본적으로 우리가 구글 코랩에서 postgreSQL작업해온 것은 autocommit=True 모드였음
- 만일 특정 작업을 트랜잭션으로 묶고 싶다면 BEGIN과 END(COMMIT)/ROLLBACK으로 처리
- autocommit = False
- 모든 레코드 수정/삭제/추가 작업이 COMMIT 호출될 때까지 커밋되지 않음
- BEGIN과 END(COMMIT) 사이에 INSERT가 있다면, END 나오기 전까지 INSERT명령이 실행되지 않고 있음
- autocommit = True
2. 트랜잭션 방식
- Google Colab의 트랜잭션
- 기본적으로 모든 SQL statement가 바로 커밋됨 (autocommit = True)
- 이를 바꾸고 싶다면 BEGIN;END; 혹은 BEGIN;COMMIT을 사용 (혹은 ROLLBACK;)
- psycopg2의 트랜잭션
- autocommit 이라는 파라미터로 조절가능
- autocommit = True 가 되면 기본적으로 postgreSQL의 커밋모드와 동일
- autocommit = False가 되면 커넥션 객체의 .commit()과 .rollback()함수로 트랜잭션 조절 가능
- 무엇을 사용할지는 개인 취향
3. DELETE FROM vs. TRUNCATE
- DELETE FROM table_name (not DELETE*FROM)
- 테이블에서 모든 레코드 삭제
- vs. DROP TABLE table_name (테이블 자체를 지움)
- WHERE 사용해 특정 레코드만 삭제 가능
- DELETE FROM raw_data.user_session_channel WHERE channel = 'Google'
- TRUNCATE table_name도 테이블에서 모든 레코드를 삭제
- DELETE FROM은 속도가 느림
- TRUNCATE이 전체 테이블의 내용 삭제시에는 여러모로 유리
- 하지만 두 가지 단점
- TRUNCATE는 WHERE를 지원하지 않음
- TRUNCATE는 transaction을 지원하지 않음 (ROLLBACK 안됨)
4. 트랜잭션 실습
DROP TABLE IF EXISTS adhoc.rollingsnowball_name_gender;
CREATE TABLE adhoc.rollingsnowball_name_gender (
name varchar(32),
gender varchar(16)
);
INSERT INTO adhoc.rollingsnowball_name_gender VALUES ('Ben', 'Male'), ('Maddie', 'Female');
-- AUTOCOMMIT=True 라서 그냥 바로 추가됨import psycopg2
# Redshift connection 함수
def get_Redshift_connection(autocommit):
host = "learnde.cduaw970ssvt.ap-northeast-2.redshift.amazonaws.com"
redshift_user = "guest"
redshift_pass = "Guest1!*"
port = 5439
dbname = "dev"
conn = psycopg2.connect("dbname={dbname} user={user} host={host} password={password} port={port}".format(
dbname=dbname,
user=redshift_user,
password=redshift_pass,
host=host,
port=port
))
conn.set_session(autocommit=autocommit)--autocommit에 어떤 값이 주어지느냐에 따라 달라짐
return connconn = get_Redshift_connection(False)
cur = conn.cursor()cur.execute("SELECT * FROM adhoc.keeyong_name_gender;")
res = cur.fetchall()
for r in res:
print(r)cur.execute("DELETE FROM adhoc.keeyong_name_gender;")
# SELECT는 상관없었으나, DELETE는 아까 (AUTOCOMMIT을 False로 설정했기 때문에 이 세션 내에서만 실행이 commit된 상태다)cur.execute("COMMIT;")
# conn.commit()는 동일한 결과를 가져옴. cur.execute("ROLLBACK;") conn.rollback()
conn.close()더 pythonic하게 처리하는 방법 : try - except를 활용한다.
conn = get_Redshift_connection(False)
cur = conn.cursor()
try: # 에러없이 잘 실행되면 commit까지 진행
cur.execute("DELETE FROM adhoc.rollingsnowball_name_gender;")
cur.execute("INSERT INTO adhoc.rollingsnowball_name_gender VALUES ('Claire', 'Female');")
conn.commit()
except (Exception, psycopg2.DatabaseError) as error: #에러가 생기면 rollback함
print(error)
conn.rollback()
finally :
conn.close()autocommit= True로 놓고, BEGIN; END;를 활용해도 된다. 둘 사이에 있는 명령 수행 중에 에러가 발생하면 롤백
conn = get_Redshift_connection(True)
cur = conn.cursor()
cur.execute("BEGIN;")
cur.execute("DELETE FROM adhoc.rollingsnowball_name_gender;")
cur.execute("INSERT INTO adhoc.rollingsnowball_name_gender VALUES ('Benjamin', 'Male');")
cur.execute("END;")3. 기타 고급 문법 소개와 실습
알아두면 유용한 SQL 문법들
1. UNION, EXCEPT, INTERSECT
- UNION (합집합)
- 여러 개의 테이블들이나 SELECT 결과를 하나의 결과로 합쳐줌
- UNION vs UNION ALL : UNION은 중복을 제거
- 각 SELECT문의 필드들의 수와 타입이 동일해야함
- 다른 소스에서 생긴 레코드들을 묶어서 새로운 테이블들을 만들 때 아주 유용
- 예를 들면 물건 판매를 Shopify와 Amazon에 동시에 한다면 각 사이트에서 판매 레코드들을 UNION으로 묶어서 새로운 테이블을 생성가능 (CTAS)
- EXCEPT(MINUS)
- 하나의 SELECT 결과에서 다른 SELECT 결과를 빼주는 것이 가능
- 기존 요약 테이블의 로직을 수정하는 경우 수정 전후를 비교하거나 하는데 많이 사용됨. QA용으로 아주 유용함
- EXCEPT 대신 MINUS를 사용해도 됨
- 각 SELECT문의 필드들의 수와 타입이 동일해야함
- INTERSECT (교집합)
- 여러 개의 SELECT문에서 같은 레코드들만 찾아줌
2. COALESCE, NULLIF
- COALESCE(expression1, expression2 ...)
- 첫번째 expression부터 값이 NULL이 아닌 것이 나오면 그 값을 리턴하고 모두 NULLdlaus NULL을 리턴
- NULL값을 다른 값으로 바꾸고 싶을 때 사용
- NULLIF (expression1, expression2 ...)
- expresson1과 expresson2값이 같으면 NULL을 리턴
3. LISTAGG - groupby aggregate
- GROUP BY에 사용되는 aggregate 함수 중의 하나
- 사용자 ID별로 채널을 순서대로 리스팅
SELECT userid, LISTAGG(channel) WITHIN GROUP (ORDER BY ts) channels #WITHIN ~으로 그룹 안에서 정렬 FROM raw_data.user_session_channel usc JOIN raw_data.session_timestamp st ON usc.sessionid = st.sessionid GROUP BY 1 LIMIT 10;- out>
- useridchannels
- 26 YoutubeGoogleNaverFacebookFacebookGoogleGoogleFacebookOrganicOrganicOrganicOrganicFacebookNaverNaver......
- 띄어쓰기도 없이 붙어서 출력되어 눈에 잘 안들어오기 때문에 delimeter를 인자로 넣어줄 수 있다
4. WINDOW함수
- syntax: function(expression) OVER([PARTITION BY expression][ORDER BY expression])
- ROW_NUMBER OVER
- SUM OVER
- FIRST_VALUE, LAST_VALUE
- math functions: AVG, SUM, COUNT, MAX, MIN, MEDIAN, NTH_VALUE
4. LAG - 내 앞, 혹은 뒤에 있는 특정 field의 값을 읽어오는 것
- 어떤 사용자 세션에서 시간순으로 봤을 때
- 앞 세션의 채널이 무엇인지 알고 싶다면?
- 혹은 다음 세션의 채널이 무엇인지 알고 싶다면?
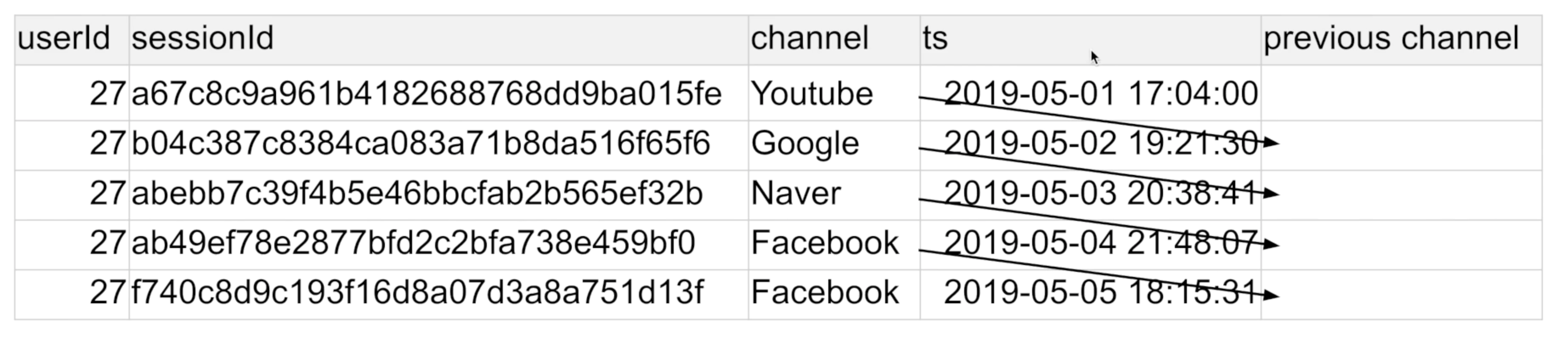
-
-- 이전 채널 찾기 SELECT usc.*, st.ts, LAG(channel, 1) OVER (PARTITION BY userId ORDER BY ts) prev_channel FROM raw_data.user_session_channel usc JOIN raw_data.session_timestamp st ON usc.sessionid = st.sessionid ORDER BY usc.userid, st.ts LIMIT 100;
--다음 채널 찾기
SELECT usc.*, st.ts, LAG(channel, 1) OVER (PARTITION BY userId ORDER BY ts DESC) next_channel
FROM raw_data.user_session_channel usc
JOIN raw_data.session_timestamp st ON usc.sessionid = st.sessionid
ORDER BY usc.userid, st.ts
LIMIT 100;6. JSON parsing 함수 - JSON 형태의 텍스트를 읽어오는 경우
- JSON 포맷을 이미 아는 상황에서만 사용가능한 함수 (구조를 모르는 상황이라면 redshift같은 경우는 UDF라고 내가 직접 만든 함수를 활용
- JSON string을 입력으로 받아 특정 필드의 값을 추출가능(nested 구조)
- ex> JSON_EXTRACT_PATH_TEXT (outer -> inner 순으로)
- SELECT JSON_EXTRACT_PATH_TEXT('{"f2":{"f3":"1"}, "f4":{"f5": "99", "f6": "star"}}', 'f4', 'f6');
4. 맺음말
'Data > SQL' 카테고리의 다른 글
| MYSQL TABLE 만들기 - CREATE TABLE (0) | 2021.11.23 |
|---|---|
| MYSQL TABLE 삭제하기 - DROP TABLE (0) | 2021.11.23 |
| [AI class W11 D4] SQL Analysis 4 (0) | 2021.07.17 |
| [AI class W11 D3] SQL Analysis 3 (0) | 2021.07.07 |
| [AI class W11 D2] SQL Analysis 2 (0) | 2021.07.07 |